
【勉強会】開発生産性の観点から考える自動テスト【サポーターズCoLab】
https://supporterz-seminar.connpass.com/event/342861
に参加してきたので、そのときのレポートです
資料
なぜ自動テストを書くのか
「コスト削減のために自動テストを書く」はアンチパターン
学習コスト・保守コスト(その他にも)という別のコストが生まれてしまう
そのため、コスト削減を目的にしていると
「学習・保守コストが高いな」「自動テストしててもコスト削減になってなくない?」
となったときに、「手動テストに戻ろうか」となってしまう。
ではなぜ自動テストを書くのか(目的を何にするのか)
それは変更容易性を保ちながら、変化に対応するため
- 変化できる特性を残しておく
- そもそもソフトウェアは「ソフト(変更容易)」であり、変化に対応できるという特性がある
コスト削減が目的ではなく(これも副次的に得られるが)
主目的は、変更容易にし、ソフトな状態にするため
テスト自動化と企業の業績の因果関係
ITパフォーマンス(業績)が高くなる指標として
- “信頼性の高い”自動テストが備えられている
- 開発者が容易に変更ができる
がある
信頼性が高い自動テストとは?
「テストが通ったから大丈夫!リリース工程進めようぜ!」が言えたり
「テスト落ちてるってことはバグがあるってことじゃん、テスト結果をみて修正しようぜ!」
が言える状態であること。(超意訳)
逆に
「テストが通ったけど、本当に大丈夫…?一応手動でもテストしといたほうがいいかな?」とか
「テスト落ちてるけど、たまに落ちることあるし、なんか上手くいってないだけで実は大丈夫なんちゃうん?」
みたいな考えが浮かぶのは信頼性が高くない。(超意訳)
これは、本来
- テスト通ってるから実装は正しい
- テスト落ちてるから実装は間違い
というシンプルな判断ができ、そこから行動に移すことができるべきであるが、
信頼性が高くないと
- テストが通ってる
- ということは実装が正しい
- が、実は実装は間違っているかもしれない
- テストが落ちている
- ということは実装が間違っている
- が、実は実装は正しいかもしれない
という4パターンの判断が求められる。
それは、テスト結果から判断してすぐに行動に移すことから遠ざかってしまう。
- 疑陽性
- 火災報知器に例えるなら、火がないのに警報が鳴ってること
- 偽陰性
- 火災報知器に例えるなら、火が出てるのに警報が鳴っていないこと
これがあると、テストが成功しているのかどうかを疑ってしまうし
テストが落ちてても誤検知で実は大丈夫なんじゃ?となってしまう。

図の不要な2つを無くしていきたい
やっかいなパターン
信頼不能テスト
プロダクトコードやテストコードに全く変更を加えていないのに、テストが通ったり落ちたりする
例えば、ネットワークに関わる部分とか、画面のテストでコード以外の状況が関係してくるとか。
これが全体の1%ほどになってくると、テストの信頼が失われ始めるらしい。
もろいテスト
プロダクトコードを少し変更したらすぐに落ちるテスト
ふるまい以外の部分(プライベートメソッドの実装とか)に依存するようなテストをしていて、
ふるまいが変わっていないのにテストが落ちてしまうとか
自作自演
テスト対象になってなかったり、アノテーションでスキップされてたり
間違った実装を正しい実装だとテストで評価してしまっていたり
その他
カバレッジ100%だと、逆に信頼しすぎてしまったりもする
テストがそもそも足りてない(仕様を満たせてない実装になってるとか)のに100%とか
テストの実行結果の扱い
情報として扱う
※データではない
ここでいう情報というのは、それによって人間の行動が変わること
実行結果の扱いの違い
- Execution Error
- プロダクトコードの実行エラー
- これが起きたら、trace とかを読んでどこでエラーになってるのかなとか見たりする
- Assersion Failure
- テストコードのアサートエラー
- これが起きた場合は、Execution Error のときと比べて解消のための動き方が変わってくる
- プロダクトコードが本当に間違ってるときもある
- テストコードが間違ってるときもある
- アサートエラーの結果を見てもどっちか分からないときもある
例えば、assertTrue だと、「期待値が true になってるけど、実際は false だよ」ってだけ言われても
何が原因なのかが分からない。
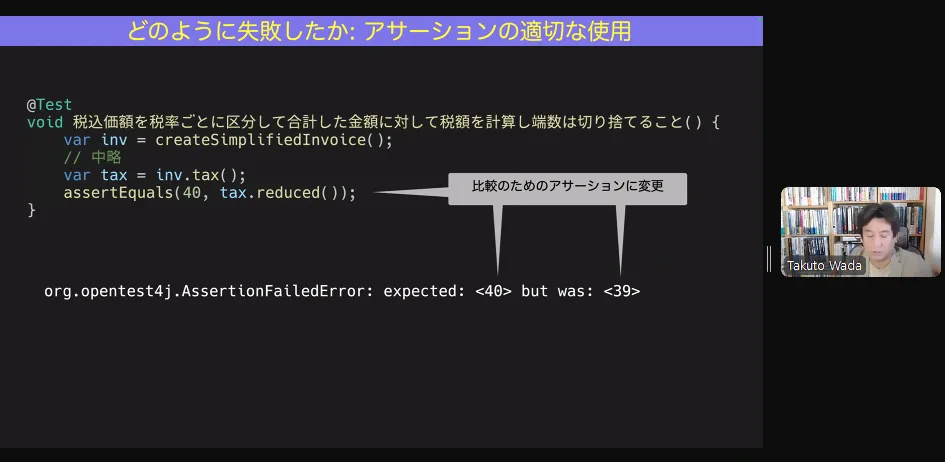
そこで、assertEquals にして結果が「期待値は 40 だけど、実際は 39 でした」だと、テストコードかプロダクトコードが間違ってるかもしれないし「期待値は 40 だけど、実際は 0 でした」だと、明らかにプロダクトコードが間違ってそうだとかの見当がつけられる。
みなさんの考えるUnitテストとは?
ここで、参加者からの回答をチャットで募ったが、回答にかなりバラつきがあった。
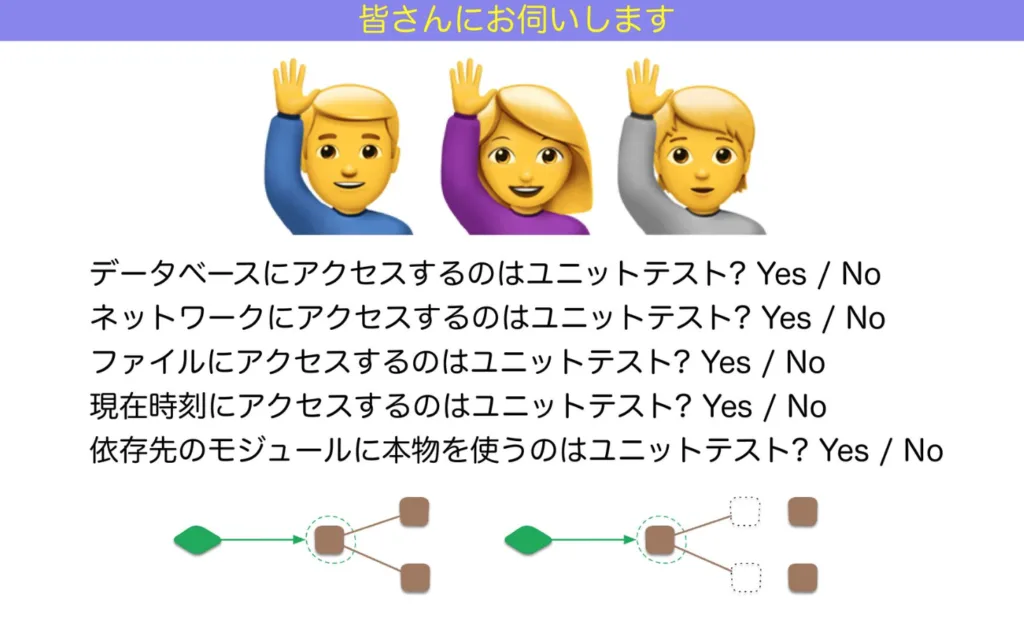
ここで言いたいことは、正解はこれですということではなく
人によって考えてるUnitテストが違うということ
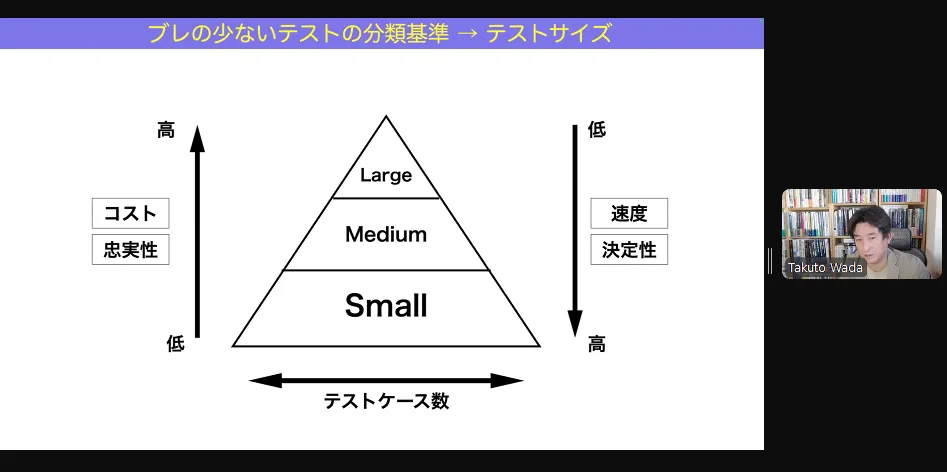
曖昧さの少ない表現
- small
- 1 マシン(実行環境)の中の、1プロセスで完結するレベル
- 通信を伴わないクラスのテストとか
- midium
- 1 マシン(実行環境)の中で完結するレベル
- ローカル環境のDBとの通信が発生するテストとか
- large
- 1 マシン(実行環境)の外に依存しないと完結しないレベル
- 外部への通信を行うとか
small なテストは高速にテストを実行でき、また信頼性も高い
ただし、large なテストが悪いという意味ではなく、
large であってもしないといけないテストもある(ここに欠陥があると致命的なのでテストはしなければ危ない等)。
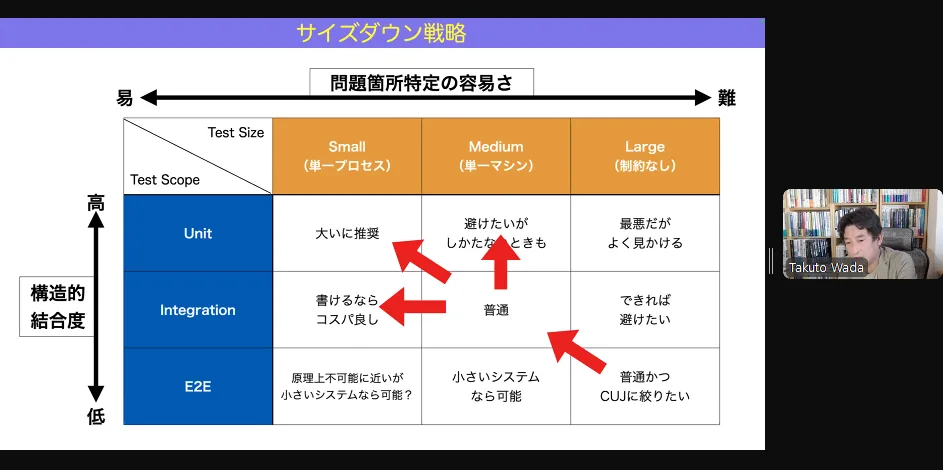
コスパよくテストするためには
small でできる範囲や量を増やしていって、large じゃないと本当にできないところだけに絞ってやるのがよい。
テストピラミッド
テストピラミッドの図形
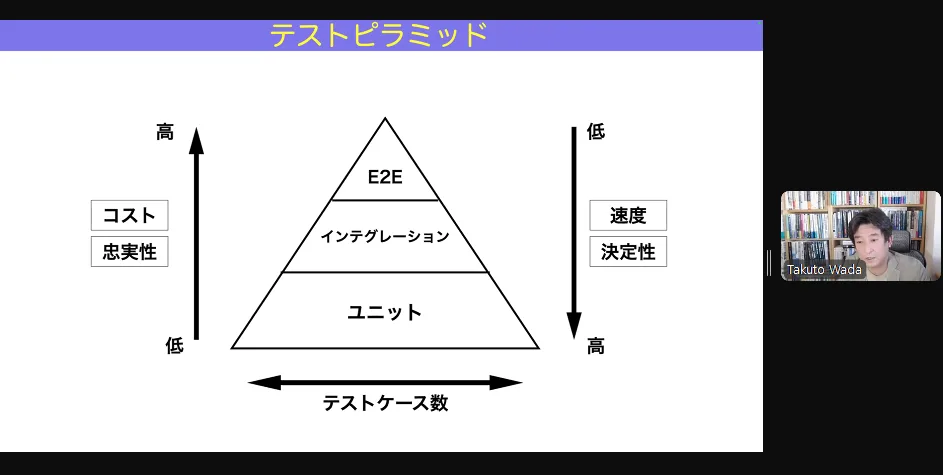
が、ピラミッドではなくこうだという図形もある。
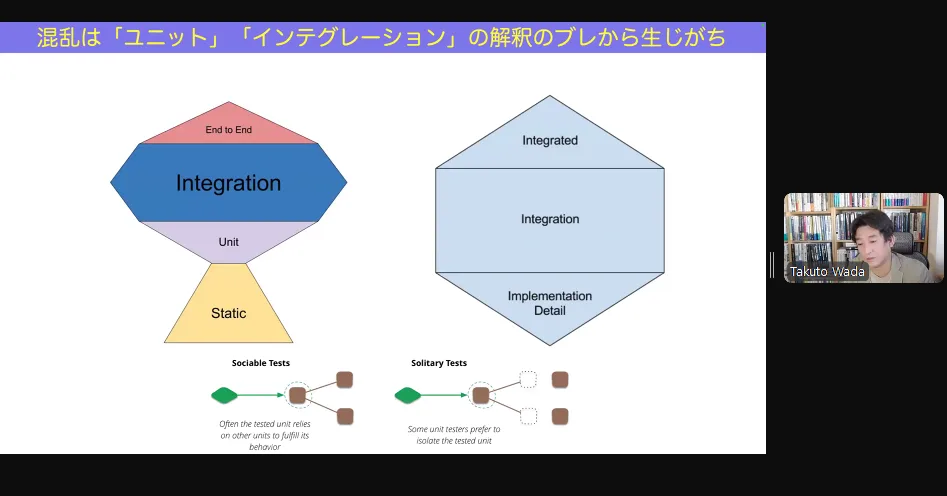
図形はこれが正解という話ではなく、
先程の話のUnitテストの解釈がそれぞれ違うから形が異なっているということ。
そこでおすすめなのが、さっきもでてきた「サイズで考える」ということ!
サイズで考えると、どの図形もこんな感じになるよ!
まだアイスクリームコーン型の現場
アイスクリームコーンが悪いという話ではない。
最初からテスト書いてるプロジェクトばかりではないのも事実なので、そこは受け入れる。
だが、自動テストに移行してはいきたい。
まずは、手動の部分を徐々に自動のE2Eテストに置き換えようという部分から始めるのがいいかも。
だが、そこに注力して満足して終わるとよくない。
なぜならそれは large なテストでコスパ悪いから。
更に、だんだん midium なテストにしていって(TestDouble を使ったりして)
徐々にピラミッド型にしていくのを目指したい。
聴講しての個人的な感想
自作自演の話について、自分もよくみかけたなぁと思い出した。
ただ、当初自分もテストコードをよく分かってなく、
周りのテストコードを真似て自作自演のテストを自分も書いたりしていたこともあった。
そしてそのときは、おそらく周囲のほとんどの人も、周りのコードを真似て書いていた。(と思う)
テストコードを書く文化自体はあったので、テストの目的とか基礎知識的なところの学習が当時あれば
もっと良かったかもなぁと思った。
途中コスパっていう単語が出てきて、自分の中でコスパが良いテストってなんだろうと考えたら
「時間が無限にあるなら large テストをたくさんしても良い。large テストのほうがより本番に近い状態でテストができるので、時間を度外視するなら large で全部やるほうがバグの発見や問題がないことの確認はよりできる。ただ、現実に無限の時間はないので、適材適所で small テストでなるべくカバーし、仕方のないところだけ large でやる」
みたいなことかなと思った。
そこで、もう一度資料をみると “自動テストの目的” に書いてある “信頼性の高い実行結果に短い時間で到達する” というのが、自分の考えともしかしたら近いのかなと思った。(違うかも?)
なるべく small なテストでやるっていうのは、副次的に「サービスが成長してテストが増えるとテスト実行結果待ち時間が長くなってしまう問題」の解消にも、少しは寄与したりするのかなと思った。
信頼不能テストで信頼が落ちてくるの分かるなぁと思った。テストが落ちた通知を「えっ!?」と思って確認したら、たまに謎に落ちるテストが落ちてて「またこいつか〜」となってたときは、確かにテストが落ちることへの感覚は鈍くなってたかもしれない。
実行結果の出力を意識した assert の使い方は、たしかになぁ〜と思った。
DynamoDB Local を使えば、Dynamo DB のテストが local でできる(つまり midium なテストができる)んですね。知らなかった。2021年からあったっぽい?今後は「なるべくローカルで完結するような環境にできないかな」という視点でも考えるようにしてみよう。
Unitテストの解釈の違いの話で、Unitって言葉があまり良くなかったりするのかなぁと思った。だからと言って別の良い言葉は浮かばないけど。日頃から「UnitテストのUnitってなんだろう」とよく思う。
あと、今日の話を聞いてどこら辺からどこら辺までがUnitテストなのか良い意味で尚更よく分からなくなった。分からなくなったということは、逆に理解が進んでいるのかもしれないと思った。

“良い設計が浮かんだり、改善したほうが良いところが見つかったりしても、すでに動いているコードを壊すのが怖いという不安が改善の手を止め“の部分は、本当にそうだよなぁと思った。以前までは良かったコードも時間が立つと良くないコードになることもあるし、不具合が見つかって根本解決したくても「影響範囲が広すぎるから…」となって局所的な暫定対応だけで終わってしまうことがある。考えはあるのに行動に移せないのはもったいないし変化に置いてけぼりになってるなぁと思っていた。安心と自信を持ってコードを編集できるようにしていきたい。
t_wada さんの資料は、何かで流れてきたときによく内容を見てはいましたが、今日は久しぶりにライブで話を聞きました。
資料だけでは知れないことがたくさん知れて、とても学びが多くライブで聞けて良かったです。